

Over the last year, the media has tended to lump the term “AI” – that is, artificial intelligence – to mean ‘anything where a computer is going to make me a finished product.’ The news is filled with discussions surrounding programs like ChatGPT and Midjourney: about their efficacy, potential scenarios for application, and the ethics surrounding their usage. Many more professionals are asking, what comes next? And, will AI make our lives easier or harder in the workplace? Library professionals are examining things like whether or not ChatGPT can be used to assist cataloging, or if ICR (intelligent character recognition) could reliably assist with digitization and metadata generation of special collections materials.
Backstage has been working with Doxie AI, a company that specializes in using proprietary AI software to extract structured data from unstructured formats. We sat down with Vijay Singh to talk about what this means for libraries and why Doxie AI is distinguished among our preconceptions about artificial intelligence software.
What does Doxie AI’s programming accomplish?
One of Doxie’s initial projects was in collaboration with UC Berkeley. A collection of entomological photographs contained images of insects alongside accession numbers and other collection data, as well as, typically, handwritten scientific names. These labels were not always in the same place, nor the same size, from photo to photo, and we all know that relying on OCR can be spotty when dealing with handwriting. For all of these reasons and more, most libraries would be forced to do slide-by-slide manual entry of the metadata which could take months, or years – in fact, for seven years, UC Berkeley did just that. Crowd-sourced annotation managed to process 70 thousand images.
Doxie AI developed a pipeline in three months that could do the same job in a matter of a couple of days.

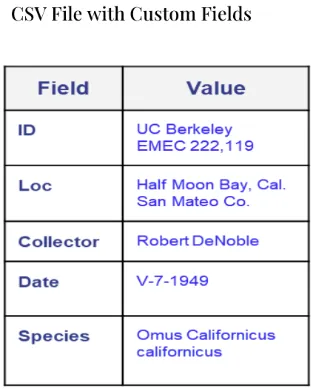
Here’s another example, one that was just spotlighted in the July-August 2023 issue of Archival Outlook. During World War II, Japanese Americans were forcibly removed and incarcerated. A WRA-26 “Individual Record” form was used “to collect sociological, demographic, and biological data about individuals held in WRA camps.” (Ellings, Friedman, Singh 2023, 11) Rather than catalog 110,000 of these forms by hand, Doxie instead worked from TIFF images that had been captured by Backstage Library Works to apply a custom AI solution. This included image segmentation and OCR, to collect data, order it, and deliver structured metadata into CSV and JSON exports.
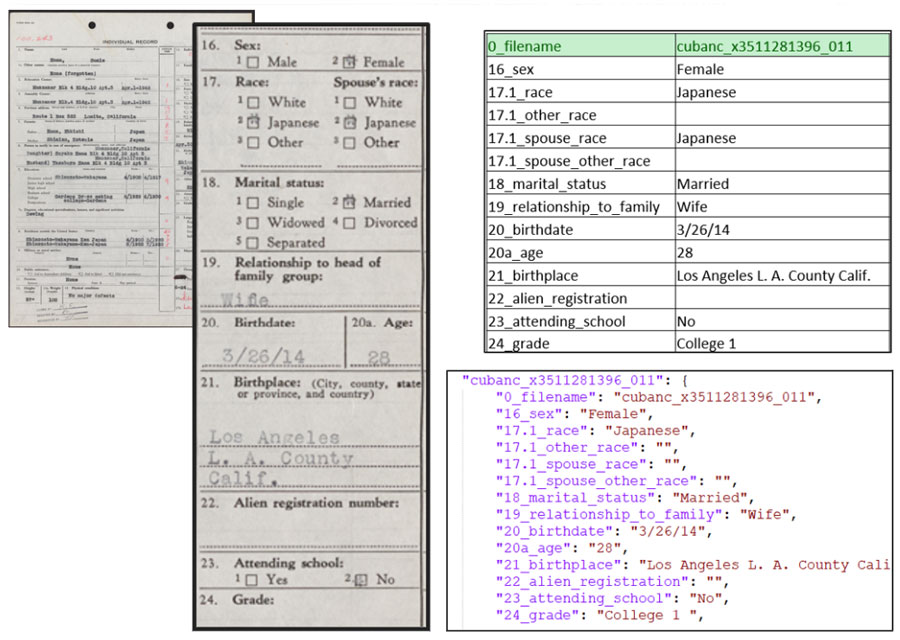
Vijay discussed this project more with us. “We delivered better than 90% accuracy for most of the fields except a few that were occluded by stamps, signatures, etc. Even for these, we were able to employ cleaning techniques to deliver good results. Another noteworthy aspect of the project was Doxie’s ability to extract named values from fields that consisted of checkboxes. Even when the check was not inside the box, we were able to accurately extract the values.”
Other projects have consisted of library card catalog data and generating brief bibliographic records; screening a collection of illustrated menus to record item descriptions and costs through subsequent iterations; and more. Doxie is also capable of performing metadata extraction (such as names, dates, etc.) from audio.
How does Doxie AI achieve these results?
All that’s needed to begin a project with Doxie AI is source material that is of high-enough quality to be interpreted by an AI program, and a logical plan for how the information contained therein should be ordered in an end product. For this, Doxie works closely with their partners that own the data and have rich subject knowledge. For visual formats, the information contained on clear, high-resolution PDFs and TIFFs can be interpreted to MODS, Dublin Core, and more.
Doxie utilizes machine learning profiles to generate an increasing value of accuracy and comprehension in their AI programming. Multiple steps – segmenting an image, generating OCR, interpreting that text, processing validation checks and prior learning – are handled in a single sequence by the software to speedily process and order information.
How accurate is Doxie, and how secure?
Historically, Doxie has been able to deliver results 95% accurately. This rate of return is staggering when you consider the errors typically found in simple OCR, or just human-entered data.
“As part of each project,” Vijay explains, “we explicitly discuss accuracy metrics with our partners. Our team does human extraction of random samples to prepare ‘ground truth’ and iterate in our development until we can meet, or beat, the accuracy targets. We also do a review of the output data before submitting it to our partners.”
What I believe truly distinguishes Doxie from other AI tools we hear about in news is this: that data processed through Doxie is fully secure, private, and encapsulated within the processing project the library has agreed upon. To put it a different way: the information that you share with Doxie goes no further. It’s not cannibalized to support future data projects. The processing program may be adopted for other libraries embarking on similar projects, but the data itself is not used as an index, as with ChatGPT or other AI on the market. There’s no copyright risk, and there’s certainly not an ethical one, either.
Next Generation of Automation Capabilities
Backstage offers automation to libraries, typically with relation to authority control processing. Technology is growing and it’s exciting to be talking about a new advent of data processing and automation that has been made available through AI and machine learning. Internally, we are testing new approaches for AI. Alongside Doxie, we’re working with clients to identify projects that could benefit from an automated approach.
Curious to know if your upcoming, or ongoing, project could benefit from Doxie’s customized AI workflow? Call us at 1.800.288.1265, visit us online at www.bslw.com, or send an email to info@bslw.com.
References
Mary Ellings, Marissa Friedman, and Vijay Singh, “Using AI and Machine Learning to Extract Data,” Archival Outlook (July/August 2023): 11, https://mydigitalpublication.com/publication/?m=30305&i=798391&p=12&ver=html5


